
¿Qué tal, malditas y malditos? Un martes más, las vacaciones no son excusa para faltar a nuestra cita y os traemos el esperado consultorio tecnológico de la semana. ¿Has oído hablar del filtro burbuja? Es un aislamiento comunicativo que provocan los algoritmos personalizados, y hoy os explicamos cuáles son sus riesgos y cómo podemos tratar de evitarlos en buscadores como Google.
También abordamos una pregunta legal sobre si los medios de comunicación pueden usar nuestras imágenes personales de redes sociales sin permiso y nos adentramos en dos de los bots más famosos de Twitter para entender cómo funcionan los bots buenos: RecuerdameBot y Colorize_Bot.
Esperamos resolver vuestras inquietudes digitales, pero la semana que viene volvemos con más periodismo tecnológico, así que recordad que podéis mandarnos todas las preguntas que queráis a nuestro Twitter o a nuestro chatbot de WhatsApp (+34 644 229 319), en este formulario o mandando un mensaje al correo [email protected]. ¡Sigue haciendo scroll!
¿Qué es el filtro burbuja de Google? ¿Podemos evitarlo cuando hacemos una búsqueda?
Seguro que alguna vez has hecho una búsqueda en Google a la vez que un amigo para buscar un viaje o con un compañero de trabajo para obtener información, y te has fijado en que no arroja exactamente los mismos resultados o no lo hace en el mismo orden. Amiga maldita, amigo maldito, has descubierto el filtro burbuja.
Este efecto es el resultado de los algoritmos que responden a lo que buscamos o que definen nuestro timeline en una red social. Lo que hacen es utilizar la información que tienen sobre nosotros para devolver una búsqueda personalizada en el caso de un buscador como Google o los resultados que más te puede gustar ver en Twitter o Instagram.
Esto provoca un sesgo informacional, refuerza creencias y nos aísla de otros puntos de vista. Por eso se produce un efecto “burbuja”. El término fue acuñado por el ciberactivista Eli Pariser en el libro ‘Cómo la red decide lo que leemos y lo que pensamos’, y lo define como una burbuja comunitaria en la que navegamos donde nuestros contactos piensan como nosotros y comparten cosas afines a nuestras creencias. Precisamente, Pariser se dio cuenta cuando vio que él y sus amigos podían escribir el mismo término de búsqueda exacto en Google, y obtenían resultados diferentes en función de su información personal.
En el caso de las redes sociales, puede que lo hayas notado porque siempre aparecen publicaciones de las mismas personas una y otra vez, mientras que hay algunos perfiles que parece que jamás suben contenido porque nunca las vemos. También parece que los tuiteros que seguimos tienen todos la misma ideología o las mismas opiniones. Repite conmigo: filtro burbuja. En este otro artículo ya os explicamos cómo se nutren las plataformas de nuestra huella digital y qué podemos hacer para evitarlo en Facebook, Twitter, Instagram y YouTube.
¿Pero qué pasa con los buscadores, en particular con Google, donde quizá es más difícil darse cuenta? Ese es uno de los principales problemas. “Una de las principales características es que pasa inadvertido, no somos conscientes de que nos han metido en ese filtro. Es peligroso pensar que lo que encuentras en Google es la realidad”, señala a Maldita.es Laura Teruel, profesora titular de Periodismo de la Facultad de Ciencias de la Comunicación de la Universidad de Málaga.
Como cuenta la experta en este artículo en The Conversation, en 2004 Google modificó su código para que las búsquedas que hicieran los usuarios en la plataforma del gigante tecnológico se volvieran personalizadas, es decir, estuvieran asociadas no solo a la relevancia de cada página, sino a los sitios webs que el usuario ha visitado anteriormente y a la información del usuario en las bases de datos de Google.
“En Google tenemos nuestra vida entera, muchísimos datos. Google sabe perfectamente que hemos estado de vacaciones en Andalucía. Basándose en nuestros gustos previos, puede arrojar resultados personalizados que, en realidad, contentan a la gente, porque afina y les da lo que están buscando. Pero, a la vez, estás recibiendo una realidad segmentada y parcelada”, explica Teruel.
Al final, desde luego que esto es eficiente para la plataforma y para el usuario pero, en realidad, se están manipulando los resultados de nuestra búsqueda. ¿Qué consecuencias puede tener esto? “Hay sesgos comerciales, pero me preocupan los efectos sociales y políticos. Se pueden generar estados de ánimo y sociales peligrosos, y puedes encontrar fácilmente una comunidad de gente que los alimenta. Por ejemplo, cuando buscas pistas porque tienes síntomas y vas al Doctor Google”, añade la experta.
Google no es el único que hace esto: otros buscadores como Bing o Yahoo! también utilizan la información personal de los usuarios. Historial de búsquedas, datos de ubicación, dirección IP, identificadores de las cookies, fecha, hora, webs en las que hacemos clic primero, datos personales como la edad y el sexo… son algunos de los datos que recopilan.
La realidad es que a todos nos encanta usar muchas de las funcionalidades de Google (las que, de hecho, mejora constantemente gracias a nuestros datos, la pescadilla que se muerde la cola). Si no quieres salir de Matrix y prefieres seguir conectado a la máquina de Google, vamos a ver al menos cómo hacerlo para intentar evitar ese filtro burbuja.
- Cierra la sesión de Google y elimina el historial de búsqueda. Sin embargo, hay que tener en cuenta que, desde 2009, la búsqueda personalizada de Google se aplica a todo usuario que acceda al buscador sin necesidad de que tenga abierta su cuenta de Google. O sea, que por cerrar nuestra sesión, no nos escapamos. Hay que hacer más.
- Revisa la configuración de tu cuenta de Google para limitar los datos que pueden obtener. Como hemos dicho, Google también tiene en cuenta factores personales que no son dictados por el individuo, como el dispositivo y la ubicación.
- Borra o desactiva las cookies del navegador, esos pequeños archivos de texto que guardan información de sitios web cada vez que los visitamos. Las podemos eliminar manualmente con frecuencia y también existen extensiones del navegador que las borran.
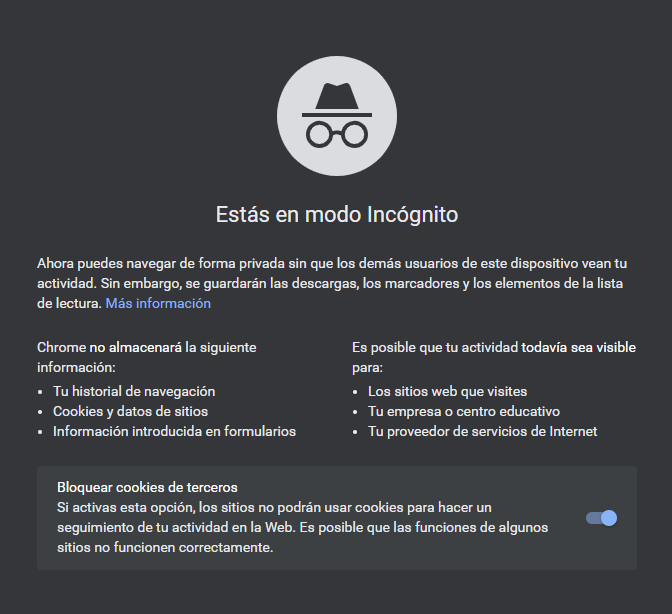
- Navega en modo incógnito. Después de haber hecho todo lo anterior, es hora de abrir esa ventana mágica con sombrero y gafas para entrar en el modo incógnito. Por ejemplo, el navegador Chrome (de Google, recordemos) te informa de que no almacenará el historial de navegación, las cookies y datos de sitios, y la información introducida en formularios si navegas en este modo.
- Utiliza extensiones o plugins para bloquear la publicidad del navegador. Los anuncios personalizados son parte de la burbuja de filtros y también generan datos que pueden usarse para recomendarnos a su vez más publicidad. Puedes eliminarlos con bloqueadores de anuncios, pero acuérdate de buscarlos en el repositorio oficial del navegador como te recordábamos en este artículo en Maldita.es (si usas Google Chrome, desde la Chrome Web Store).
- Usa buscadores alternativos, como DuckDuckGo (el más conocido que encabeza la lista de los buscadores, aunque ha habido alguna polémica últimamente), Startpage (focalizado en la privacidad y que asegura que no recopila ninguna información personal) o Ecosia (declara en su política de privacidad que no crea perfiles personales basados en el historial de búsqueda, ni utiliza herramientas de rastreo externas como Google Analytics).
En cualquier caso, evitable o no, el consejo más importante es ser consciente de que este filtro burbuja existe, tanto en Google como en redes sociales, y observar con ojo crítico y objetivo. Teruel recuerda que “debe ser un ejercicio activo buscar otros puntos de vista, estar alfabetizados y ser críticos con lo que nos devuelve el buscador”.
En este otro artículo de The Conversation, se recopilan algunos consejos para hacer búsquedas efectivas y críticas en internet, por ejemplo, elegir qué tipo de buscador necesitamos según nuestra necesidad, optar por buscadores especializados y completar la información con otro tipo de fuentes y portales como bases de datos o bibliotecas virtuales. Que está muy bien tener Google de página de inicio, pero hay más opciones.
¿Pueden los medios de comunicación usar tus imágenes personales de YouTube u otras redes sociales sin permiso?
Si eres usuario de Twitter, seguro que te va a sonar esto que habrás visto en más de una ocasión: ha ocurrido algo que se ha hecho viral y una persona que estaba en el momento y lugar adecuados ha subido un vídeo a la red social; debajo, en comentarios, suelen abundar periodistas pidiendo permiso para usar las imágenes en su medio de comunicación.
Esa sería la situación ideal en ese caso. Sin embargo, a veces, esto no se cumple. Y otras veces, hay un añadido más complejo legalmente: que en esas imágenes que usa el medio de comunicación obtenidas de una red social aparezca una persona reconocible. ¿Es legal hacer esto? ¿Puede un medio de comunicación coger imágenes de redes sociales a su antojo? La respuesta es, depende.
El 28 de julio se cerró un caso paradigmático. Un grupo de comunicación había sido condenado por usar imágenes de la vida privada de un detenido por narcotráfico que habían sido subidas por su hijo a YouTube. Sin embargo, después de que el grupo interpusiera un recurso de casación, el Tribunal Supremo ha considerado que prevalecía el carácter informativo de las imágenes.
Como recoge Europa Press, “en el juicio de ponderación de los derechos fundamentales en conflicto, prevalece el derecho a la información del medio de comunicación sobre el derecho a la propia imagen del demandante". Cada caso tiene sus aristas concretas, pero vamos a utilizar este ejemplo para explicar qué significa todo esto y qué circunstancias pueden darse.
Los dos derechos fundamentales que menciona la sentencia son el derecho a la propia imagen de una persona física, recogido en la Ley 1/1982, y el derecho a comunicar o recibir libremente información veraz por cualquier medio de difusión del artículo 20.1.d de la Constitución Española.
La Ley 1/1982 dice que solo con el consentimiento de la persona se puede difundir su imagen, pero hay algunas excepciones, indica Samuel Parra, abogado especializado en protección de datos en ePrivacidad, a Maldita.es. “Cuando la imagen se toma de una persona que está ejerciendo su cargo público en el momento de la imagen y cuando la persona aparece en la imagen de forma accesoria. Por ejemplo, si hacemos una foto de un accidente de tráfico y de fondo hay unas personas que están mirando, no son el foco, sino que aparecen de fondo”, explica Parra.
Además, según la Ley Orgánica de Protección de Datos (LOPD), la imagen es un dato personal porque nos identifica y, por lo tanto, está protegido, como hemos explicado en otras ocasiones en Maldita.es.
En el otro derecho fundamental, el artículo 20.1.d de la Constitución, se recoge la “libertad de los medios de comunicación de difundir información que se considere interés periodístico o de interés general”, resume Parra. Claro, en esa difusión de información, puede haber imágenes personales.
Es en esta “colisión de derechos” donde surge el problema, como se recogía en la sentencia anterior.
“Como estos dos derechos son fundamentales, tienen el mismo nivel. Entonces, cuando colisionan, es un tribunal quien debe juzgar cuál prevalece según cada caso concreto, si el derecho a la propia imagen o el derecho a la información de los medios de comunicación”, sintetiza Parra.
¿Entonces qué? ¿Podría cualquier medio de comunicación coger una imagen personal mía y utilizarla sin mi permiso? Aquí no hay verdades absolutas ni criterios predefinidos, depende del caso. “Unas veces se considera que coger la foto de un perfil de una red social y publicarla en los medios de comunicación es una intromisión a la propia imagen del afectado, y otras veces consideran que la intromisión está justificada porque la libertad de información está por encima”.
Pero a ver, a ver… ¿Qué intromisión? ¿Si la ha subido la persona a las redes sociales, eso significa que la ha hecho pública y puede usarla cualquiera libremente, no? Si estás pensando esto, error.
Parra subraya que es importante poner el acento en que publicar una foto en Instagram o un vídeo en YouTube no significa que cualquier persona pueda usarlo o que pueda utilizarse en un medio de comunicación. “Esa fotografía sigue protegida por mi derecho a la propia imagen y yo tengo la capacidad de decidir sobre ella. No es de dominio público y utilizarla porque sí es una infracción, no todo es libertad de información”, concluye Parra.
Y no solo eso: más allá de que en este caso concreto estemos hablando de imágenes personales y por tanto del derecho a la propia imagen, el principal motivo es que todas las imágenes están protegidas por los derechos de autor. No puedes usar el contenido de otra persona en redes sociales porque no es de tu propiedad intelectual. Es decir, sobre ese contenido sobrevuelan tres leyes: la Ley de Propiedad Intelectual, la de protección de datos y la referente a los derechos a la intimidad y propia imagen. Aquí te explicamos más sobre en qué condiciones sí se podrían usar (básicamente, cuando se usan funcionalidades de la propia red social para compartir, como compartir o retuitear).
Así que, volviendo al principio, esos periodistas que piden permiso en Twitter lo están haciendo bien porque, en general, no se puede publicar en los medios de comunicación ninguna imagen personal obtenida sin consentimiento, ni ninguna imagen que no hayas grabado tú o de la que no tengas permiso de su autor o de su portador de derechos, aunque una persona la haya subido a redes sociales. Pero, en ciertas casuísticas y casos muy específicos, como el ejemplo anterior, el uso puede ser legítimo; eso tendrá que decidirlo un tribunal.
Y en el historial de sentencias de los tribunales, ¿qué prima? ¿Qué dice la jurisprudencia (el conjunto de sentencias y demás resoluciones judiciales emitidas en un mismo sentido) sobre el uso y la publicación en medios de comunicación de imágenes obtenidas de redes sociales personales sin consentimiento? Pues, en realidad, no hay tanto establecido.
“No hay mucho de jurisprudencia a instancias mayores con el tema de redes sociales, pero siempre va a primar la libertad de información si las imágenes mostradas tienen que ver con un delito”, afina Sergio Álvaro López, abogado sénior de penal en Legálitas. Por ejemplo, “si una persona roba un coche y sale en redes sociales difundiendo un vídeo con el coche robado, es como un apéndice del propio delito”.
El experto recuerda otro caso en el que el análisis vino dado porque en un periódico se había divulgado la identidad de una persona para ilustrar el suceso del que fue víctima. Aquí, el Tribunal Constitucional estableció que era una vulneración de su imagen y que los medios no pueden publicar fotos de las redes sociales sin consentimiento: “Los sucesos criminales son acontecimientos noticiables, incluso con independencia del carácter de sujeto privado de la persona afectada por la noticia. Sin embargo, el límite está en la individualización, directa o indirecta, de la víctima, pues este dato no es de interés público porque carece de relevancia para la información que se permite transmitir”.
En resumen, recoge López, “en el juicio de ponderación siempre va a primar el derecho a la información si son hechos que van relacionados con el propio hecho delictivo; si no, es una intromisión”.
¿Cómo funcionan bots buenos de Twitter como RecuerdameBot o Colorize_Bot?
En febrero de este año, Twitter incluyó la posibilidad de añadir la etiqueta “cuenta automatizada” en las cuentas de bots para distinguirlos de los perfiles administrados por personas. No en cualquier bot, claro, sino en los llamados bots buenos, aquellos que ayudan a la gente a encontrar información útil y relevante.
En Maldita.es ya os explicamos qué es un bot bueno y en qué se diferencia de otros bots, pero también nos habéis preguntado cómo funcionan exactamente, cómo se produce esa automatización y cómo están conectados con Twitter. Hoy vamos a contaros qué hay detrás de su desarrollo y cómo funcionan dos de estos bots que probablemente hayas usado alguna vez en la red social: RecuerdameBot y Colorize_Bot.
El primero es un bot que te recuerda tuits: solo tienes que responder al tuit que quieras que te recuerde diciéndole cuándo quieres que lo haga (en tres horas, en un mes, cierto día a cierta hora) y automáticamente lo hará. Al segundo puedes mandarle una imagen en blanco y negro y, en cuestión de minutos, te la devolverá en color.
¿Cómo los crearon sus ideadores? Lo primero es desarrollar el bot, es decir, escribir el código en un lenguaje de programación. RecuerdameBot está desarrollado en Python y Colorize_Bot en JavaScript.
La mayor duda por la que nos habéis preguntado es cómo se salta de ahí a Twitter, es decir, cómo se produce el puente entre el bot desarrollado y la plataforma para que haya una comunicación, se puedan obtener menciones, responder mensajes automáticamente, etc. Pues se hace “a través de la API (el medio en que se comunican dos sistemas informáticos) de la red social. Para usar la API de Twitter primero hay que registrarse como desarrollador”, explica a Maldita.es Francisco Induni, desarrollador de RecuerdameBot.
Para ello, “hay que solicitar una cuenta de desarrollador a Twitter, rellenar un formulario donde se indica el uso que le darás a la cuenta y, si la solicitud cumple las expectativas de Twitter, se aprobará. Una vez conseguido, cada desarrollador obtiene unos tokens o claves de acceso, con los que se puede ir a cualquier lenguaje de programación que soporte peticiones HTTP”, indica Asdrúbal Zambrano, desarrollador de Colorize_Bot.
Con eso, ya se puede establecer comunicación entre el programa y Twitter, y solo queda “desplegar” el código en un servidor o un ordenador para que el bot funcione durante todo el día. Ahí intervendrán los webhooks, un sistema de comunicación automático que “dispara un evento cada vez que alguien menciona al bot en Twitter”, detalla Zambrano. Es como si fuera una alarma que salta cada vez que alguien “taggea” al bot para avisarle de que hay una petición.
Vamos a entender un poquito las tripas digitales de estos dos bots, qué se cuece ahí dentro cuando un tuitero les escribe con una petición.
En el caso de RecuerdameBot, Induni nos detalla que la parte más complicada es entender el mensaje del usuario e interpretarlo para que pueda descifrar las distintas maneras en que un usuario puede pedir el recordatorio. Cuando el bot ya ha procesado en qué día y hora el tuitero quiere que le recuerden el tuit, guarda en su base de datos el recordatorio.
“Tanto los tuits como los perfiles de Twitter tienen un identificador (ID) único. Ningún ID de ninguno de los tuits existentes se repite. Por ejemplo, el ID del usuario de @RecuerdameBot es 1254452999621152775 (e incluso al cambiar el nombre del usuario de una cuenta, el ID permanece igual). Cuando el bot es mencionado, obtiene tanto el ID único del tuit como el del usuario. Entonces guarda en su base de datos estos dos identificadores y el día y horario en UTC (horario universal) en que debe recordarlo”, explica Induni.
RecuerdameBot revisa la base de datos constantemente y, cuando llega la fecha en la que hemos pedido que queremos, coge ambos ID y ejecuta el recordatorio.
Zambrano, desarrollador de Colorize_Bot, explica que en su caso cada mención se procesa y valida para ver si el tuit que mencionó al bot contiene imágenes. (Esto solo podrá hacerlo si la cuenta de Twitter es pública). Después, “se capturan las imágenes y se envían a la API de colorización de DeepAI, que devuelve una imagen coloreada en menos de seis segundos, y el siguiente paso es responder automáticamente al tuit donde se menciona al bot con la imagen coloreada”.
Esto suena increíblemente rápido pero, si hay muchas solicitudes, puede no gustarle demasiado a Twitter, ya que la red social tiene límites: 2.400 tuits diarios por cuenta, subdivididos en límites más pequeños con intervalos de media hora. Por eso, “el bot está programado para responder cada 30 segundos en caso que sean menciones seguidas para no romper esas reglas y no subir de unos 100 tuits la hora”.
Ese es uno de los problemas que podría encontrarse un bot, pero no es el único. Zambrano explica que, en su caso, le han bloqueado el bot porque hay usuarios que lo etiquetan con contenido explícito o inapropiado, así que hace una revisión manual para retirar este tipo de imágenes y bloquear al usuario. También si los mensajes automáticos que lanza el bot tienen siempre el mismo texto, Twitter lo considera spam.
“La plataforma tiene un algoritmo que constantemente revisa las cuentas y aquellas que detecta automáticamente como posibles bots de spam (o cuentas falsas) les aplica un shadowban [baneo en la sombra]: no elimina ni bloquea la cuenta pero la oculta a los demás usuarios, por ejemplo, no notificando a los usuarios que el bot menciona y no mostrando los tuits en el timeline de los usuarios que siguen al bot”, indica Induni de RecuerdameBot.
Twitter tiene su propia comunidad de desarrolladores donde se puede explorar todo lo relacionado con la API y otras herramientas, y hay muchos otros bots populares en la plataforma, como Thread Reader App, que crea una página con todo el contenido de un hilo de Twitter, o Emoji Mashup Bot, que genera nuevos emojis juntando dos existentes. También otros simplemente para pasar el rato, como Emoji Aquarium, que recrea acuarios con emojis (cada cual mata su tiempo como quiere).
Ya sabes que puedes comprobar si debajo del nombre de la cuenta de Twitter aparece “Automatizado por” para saber si es un bot bueno aprobado por la red social. ¿Y cómo se consigue esa etiqueta de automatización? Como explican ambos desarrolladores, se hace fácilmente desde la página de Twitter de la cuenta del bot: Opciones -> Tu cuenta -> Información de la cuenta -> Automatización. Dentro, el desarrollador inicia sesión con la cuenta real y aparecerá el mensaje de "Automatizado por".
Y para terminar…
No somos técnicos ni ingenieros, pero contamos con mucha ayuda de personas que son expertas en su campo para resolver vuestras dudas. Tampoco podemos deciros qué servicio usar o dejar de usar, solo os informamos para que luego decidáis cuál queréis utilizar y cómo. Porque definitivamente, juntos y juntas es más difícil que nos la cuelen.
Si tienes cualquier duda sobre esta información o cualquier otra relacionada con la manera en que te relacionas con todo lo digital, háznosla llegar: