
Es probable que en alguna ocasión hayas utilizado algún asistente de voz como Alexa, Siri o Cortana para que te diga cómo llegar a una calle, ponga una alarma o te responda a alguna que otra pregunta. Al otro lado nos contesta una voz que suena casi como si fuera una persona.
El resultado de los programas que permiten crear estas voces y que parezcan cada vez más naturales se conoce como voz sintética, y gracias a la inteligencia artificial han conseguido pasar de tener un sonido “robótico” a ser recreaciones muy creíbles, hasta el punto de que también se puede clonar el habla o el canto de otra persona. Esto hace que estas voces ya no se usen solo en estos asistentes conversacionales, sino que también tengan aplicaciones sociales y médicas, como devolver la voz a quien no la tiene porque la ha perdido por una enfermedad o una discapacidad.
A un clic, ¿de qué hablamos en este tema? Pincha para ampliar
¿Qué son las voces sintéticas? ¿Cómo han evolucionado los sistemas conversacionales?
¿Te acuerdas de Loquendo? Si no te suena, se trata de un programa que se popularizó a principios de los 2000 y que todavía hoy funciona: permite darle un texto y que la máquina lo lea en voz alta. Los resultados eran bastante artificiales y era evidente que quien estaba hablando era una máquina, no un ser humano. Pero en estas dos décadas, este tipo de programas ha mejorado notablemente.
Estas aplicaciones existen gracias a las voces sintéticas: voces generadas por software, y que son capaces de imitar nuestra forma de hablar. Nos lo explicó en la Twitchería de Maldita Tecnología Nieves Ábalos, fundadora de Monocero Labs, que detalló cómo las voces sintéticas surgen a partir de programas que son capaces de recibir texto y generar como salida “un audio con las características de una voz”.
En el caso concreto de Loquendo se trata de un sistema text-to-speech (conversión de texto a voz) y el proceso se resume en dos partes: por un lado la capacidad de la máquina de interpretar el texto escrito, y después el proceso de transformarlo en sonido. Para ello, el programa divide las palabras en diferentes fonemas, los procesa, y posteriormente los reproduce como audio.
Ábalos incide en que antiguamente este tipo de tecnología conseguía reproducir estos sonidos recurriendo a bibliotecas de audios ya grabados o a partir de un vocoder, un tipo de sintetizador de voz. Una tecnología que presenta varias dificultades para imitar de forma natural nuestra forma de hablar.
Pero gracias a la inteligencia artificial, en concreto a las redes neuronales (un modelo de inteligencia artificial que trabaja conectando datos entre sí y encontrando patrones), estas voces sintéticas ahora consiguen recrear los matices del habla y sonar mucho más realistas. La clave está en que, con esta tecnología, aprenden directamente cómo hablamos a partir de diferentes muestras de nuestra voz.
Estos avances en la tecnología también han dado lugar a la creación de modelos conversacionales orales: programas que son capaces de entender lo que decimos y que nos permiten hablar con una máquina, tal y como hacemos hoy en día con los asistentes de voz.
Para ello, el programa tiene que seguir varios pasos. El primero de todos es poder entender nuestra voz y saber cuáles son nuestras instrucciones. Para esta tarea utiliza un sistema speech-to-text (conversión de voz a texto a voz), un reconocedor de habla que permite convertir nuestras peticiones a un formato por escrito que la máquina pueda comprender.
Una vez que tiene nuestra petición en texto, el programa analiza qué es exactamente lo que le hemos pedido (por ejemplo, que nos conteste a una pregunta), elabora una respuesta por escrito, y finalmente emplea el text-to-speech para convertir esa respuesta en formato de audio.
Zoraida Callejas, Profesora Titular del Departamento de Lenguajes y Sistemas Informáticos de la UGR, nos explicó este proceso en la Maldita Twitchería Tecnológica. Durante su intervención la experta detalló que, por el momento, no se han terminado de desarrollar los sistemas que funcionen “de audio a audio”: aquellos capaces de procesar lo que decimos y darnos una respuesta directamente, sin la necesidad de esta conversión de voz a texto, y de texto a voz.
¿Qué tipos de voces sintéticas hay?
Esta tecnología no sólo se puede emplear para clonar voces, sino que también se puede usar para crear una nueva voz que no exista en la realidad, o para sustituir la voz de una persona con la de otra completamente diferente, como muestra este ejemplo realizado por Eleven Labs.
Podemos por tanto diferenciar dos tipos de voces sintéticas:
- Las voces clonadas: aquellas voces que imitan el habla, el timbre, y la prosodia (elementos como el acento, el tono de la voz, la entonación…) de una persona en concreto. Para ello, la máquina estudia varias grabaciones de un único individuo y aprende a reproducir su voz en concreto. Este tipo es el que podemos encontrar en deepfakes, pero también se pueden emplear para preservar este rasgo de una persona, como ha hecho la propia Ábalos con su voz.
- Las voces artificiales: a diferencia de las voces clonadas, que solo aprenden de un único individuo, en el caso de las voces artificiales la máquina estudia el habla de diferentes personas para crear una nueva voz que no existía antes. Este tipo de voces no pertenecen o identifican a ninguna persona en concreto, y podemos encontrarla en herramientas de accesibilidad como lectores de texto, por ejemplo.
¿Cómo se consigue crear (o clonar) una voz con IA?
Uno de los procesos clave de estos sistemas es el sintetizador de voz, el responsable de que la máquina sea capaz de generar sonido y respondernos con una voz humana que pueda imitar nuestro habla. Y aquí es donde entran en juego las redes neuronales y la inteligencia artificial.
Por ejemplo, para la creación del asistente de Google se utilizó como base la voz de la locutora Nikki García. En este caso, la actriz de voz no tuvo que repetir uno a uno el nombre de todas las calles de España (un proceso que tardaría una eternidad), sino que se tomaron diferentes muestras de su voz para poder generar un modelo capaz de imitar su forma de hablar. La propia locura detalló cómo fue este proceso en Cadena Ser.
A partir del estudio de estas muestras de voz, grabadas en estudio y con buena calidad,la máquina consigue aprender cómo hablamos para poder imitarnos. Ábalos explicó cómo funciona este proceso gracias a las redes neuronales: con el estudio de esos audios y su transcripción la máquina aprende a relacionar determinadas palabras con diferentes sonidos, cómo los pronuncia una persona en concreto, y así imita los matices de su voz.
A partir de estas grabaciones de voz se crea un modelo acústico: es decir, una representación de cómo sonamos, nuestro timbre y prosodia. Para ello, es necesario convertir ese audio en información que la máquina sea capaz de interpretar, como puede ser un espectrograma de Mel (un tipo de visualización del sonido parecida a nuestra forma de escuchar). Una vez que la máquina recibe estos datos estudia en qué frecuencias se sitúa nuestra voz, cómo pronunciamos, y finalmente aprende a imitarnos. En estos artículos (aquí y aquí) puedes encontrar más información sobre el proceso.
Después de analizar nuestra voz, la máquina es capaz de crear un modelo de lenguaje que sea capaz de imitar el habla humana. Es el caso de VALL-E, el modelo desarrollado por Microsoft que promete clonar nuestra voz con apenas tres segundos de audio, según indica en su web. Para ello, este programa ha sido entrenado con 60.000 horas de grabación.
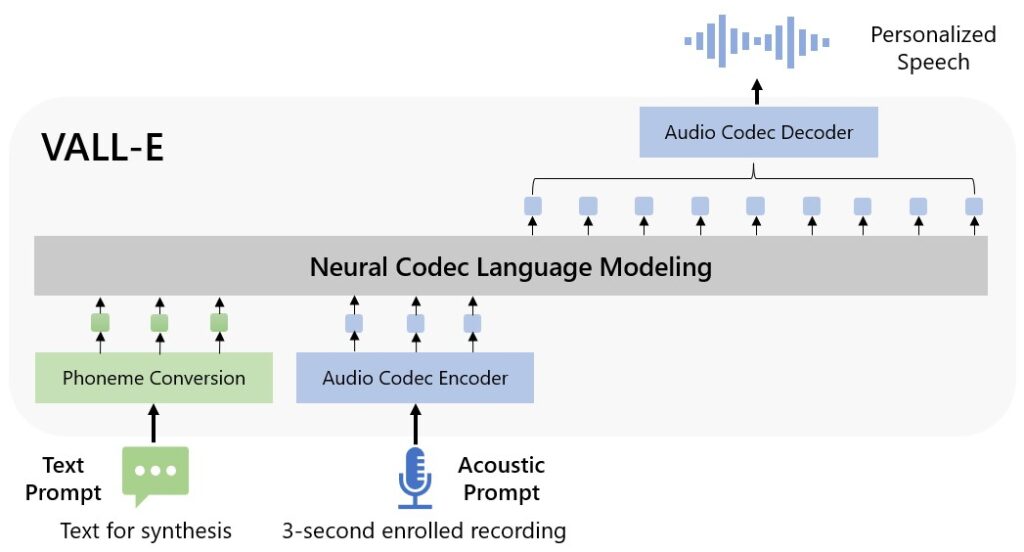
¿En qué se puede emplear esta tecnología?
Esta tecnología tiene diferentes aplicaciones. Hemos visto cómo se puede usar para crear asistentes de voz como Siri o Alexa, pero también hemos visto cómo los seguidores de Ariana Grande, Ava Max o Duki han usado estas herramientas para hacer versiones de temas que en realidad nunca han cantado.
Pero también tiene sus riesgos. Los propios creadores de VALL-E señalan que su herramienta puede ser usada para cometer fraudes y estafas, suplantando la identidad de otras personas. Desde Maldita.es ya os hemos advertido de algunos casos en los que se ha conseguido clonar la voz de nuestros conocidos para hacerse con nuestro dinero. También os hemos advertido de los peligros de compartir nuestra vida digital, y de en qué escenarios los timadores lo tienen más fácil para hacerse con muestras de nuestra voz, pero os recordamos que es muy difícil que accedan a nuestro WhatsApp a no ser que se hagan con nuestro móvil y que se requiere bastante tiempo de grabación para tener resultados de calidad.
Sin embargo, esta herramienta puede mejorar vidas. Es el caso de Álvaro Medina, periodista en Prodigioso Volcán, que nos contó en la Twitchería de Maldita Tecnología cómo gracias a Inma Hernáez, catedrática de la UPV/EHU y directora del laboratorio de investigación Aholab (especializado en el procesado digital de la voz), pudo donar su voz a su padre enfermo de ELA y mejorar su calidad de vida. Su caso no es el único.
