
¡Hola, malditas y malditos! Hoy, en el consultorio tecnológico, nos ponemos la bata médica, pero también la técnica, la legal, la ética… Explicamos si un programa de inteligencia artificial o un robot pueden cometer un delito y, en caso de accidente o infracción, quién se haría responsable de lo ocurrido. También contamos hasta qué punto son fiables los programas informáticos que dicen predecir si una persona tiene tendencias suicidas o depresivas a partir de lo que publica en redes sociales.
Os animamos a que nos mandéis más preguntas y las contestaremos en las próximas entregas del consultorio de Maldita Tecnología. Podéis mandarlas al correo [email protected], a nuestro Facebook, a Twitter o a nuestro chatbot de WhatsApp (+34 644 229 319), o si no a través de este formulario.
¿Existe algún tribunal especial, como puede ser un tribunal médico, para casos concretos de accidentes o delitos que se hayan cometido por robots o recae sobre el individuo "que lo maneja”?
Hay muchos tipos de robots pero, entre ellos, no tantos que estén programados para tomar decisiones por ellos mismos. Para ello, tendrían que funcionar con algún tipo de programa basado en inteligencia artificial que funcionase sin supervisión. Además, ¿qué entendemos por robot? Un coche autónomo podría ser un robot, pero también un dron, un vehículo de reparto, un brazo mecánico de asistencia médica… Y hasta un programa informático. Lo que tienen en común todos ellos es que no, no pueden cometer un delito.
Nos habéis preguntado cómo se dilucidan los casos en los que un robot sea el causante de un accidente o un delito. Por eso, es lo primero que tenemos que aclarar: un robot o un programa basado en inteligencia artificial no pueden cometer un delito. “Si hablamos de derecho penal, los únicos que pueden cometer delitos son las personas jurídicas o físicas, pero no las máquinas”, nos explica Fernando Miró-Llinares, director del centro de investigación CRÍMINA de la Universidad Miguel Hernández.
En los sistemas jurídicos actuales, se establece que “las máquinas no responden, responden las personas por las acciones, el diseño o las omisiones que han hecho en ese diseño”, señala. El ejemplo que más nos puede sonar es el de los coches autónomos que hayan causado algún tipo de daño a una persona. A día de hoy hay procesos de judiciales en marcha contra el conductor de un Tesla involucrado en un accidente en el que murieron dos personas en 2019, y también conocemos casos en los que se ha culpado a la empresa y a la persona conduciendo el coche, como la ocasión en la que una mujer falleció después de que le atropellará un vehículo autónomo de Uber.
“Cada una de las acciones dañinas que se podrían producir, por ejemplo, un daño patrimonial o un daño al honor o un accidente de tráfico, irían por la vía tradicional. Es decir, se tratarían exactamente igual que si fuese un caso cometido por un humano”, coincide Teresa Rodríguez de las Heras, docente y miembro del grupo de expertos en Nuevas Tecnologías, Prevención y Seguro en la Comisión Europea.
Esto es porque, como recuerda Miró-Llinares, “la máquina no puede responder”, de modo que hay que abordar el caso desde dos perspectivas: la de la responsabilidad administrativa (porque los algoritmos se hayan diseñado mal) y la responsabilidad penal porque, al fin y al cabo, ha muerto una persona y hay un daño letal. ¿Cómo se determinan los pasos a seguir? “Por medio de los sistemas que proporciona el sistema penal tradicional, o sea, por acción u omisión de sujetos individuales o empresas”, señala el especialista. Incluso en un caso como este, en el que el daño es claramente visible porque ha resultado letal, no existe una consideración legal que señale directamente al conductor del vehículo autónomo o a la empresa propietaria, sino que se analiza el caso en un proceso judicial tradicional y a partir de ahí se responsabiliza a uno u otro.
En otras situaciones, con otro tipo de tecnología, la respuesta a quién tiene la responsabilidad de un accidente de este tipo no la tenemos tan clara. Pero esto es normal, porque todavía no se ha alcanzado un consenso legal y normativo sobre a quién se le debe atribuir la responsabilidad de que un sistema inteligente cometa este tipo de infracciones.
Que son muchas y de distintos tipos: imaginaos que un robot asistencial cause algún tipo de daño al paciente al que acompaña, que se use un sistema de evaluación en un banco que clasifique mal el riesgo de morosidad de un cliente o que una cámara de reconocimiento facial identifique erróneamente a una persona como un delincuente peligroso, y que por tanto afecte a su historial de antecedentes. O incluso, volviendo al caso de los coches autónomos y por poner otro ejemplo, este bloquease la entrada de un párking y causase daños económicos o patrimoniales a una comunidad de vecinos.
Hay varias propuestas encima de la mesa sobre cómo conseguir atribuirle la responsabilidad a alguien, tal y como nos explica Rodríguez de las Heras. “Se está tratando de resolver a nivel europeo”, señala, concretamente en el grupo de expertos del que forma parte. Una de las propuestas gira en torno a la figura del “operador”. Y para considerar a alguien un operador, tienen que darse dos elementos: que sea la persona (o la entidad) que “controla” el sistema y la que “se beneficia de su uso”.
“Por ejemplo, un banco que utiliza un sistema para evaluar a sus clientes o una empresa que usa robots para hacer limpieza o una flota de taxis autónomos. No es el usuario concreto, sino aquel en el que concurre control y beneficio”, explica a Maldita.es.
Por otro lado, se debate también la posibilidad de tratar los robots y sistemas autónomos como si fueran “productos” y, por tanto, considerar que se ha producido un daño porque en realidad eran defectuosos. Pese a ser un enfoque basado en conceptos y regulaciones asentadas, sigue planteando demasiadas dudas sin una respuesta clara: “Cuando estos sistemas toman decisiones, las toman conforme a datos que se le proporcionan, que toma del entorno o que resultan de ciertas predicciones. Le pueden llevar a tomar una decisión incorrecta o a aprender erróneamente y no evaluar el riesgo. No está claro que estos sean defectos como tal”, expone Rodríguez de las Heras. O sea, que no son como una camiseta que viene con una tara o un mueble mal hecho.
Además hay otro interrogante que resolver. Esta propuesta de considerar a los robots o la inteligencia artificial como productos implicaría que el responsable del hipotético accidente sería el productor. Muy bien, ¿y quién sería este actor? ¿El programador? ¿El que proporciona los datos? ¿El que implementa el software y el hardware? “No es una solución inmediata, sino que abre muchas otras cosas a discutir”, remarca la especialista.
En su momento, en 2017, el Parlamento Europeo sugirió considerar a los robots “personas electrónicas”. El objetivo de la institución de la Unión Europea fue entonces “crear a largo plazo una personalidad jurídica específica para los robots, de forma que como mínimo los robots autónomos más complejos puedan ser considerados personas electrónicas responsables de reparar los daños que puedan causar”, según el texto del informe que presentaron. También hablaban de concederles “personalidad electrónica” si eran capaces de tomar “decisiones autónomas inteligentes” e “interactuar con terceros de forma independiente”. El calificativo “independiente” es difícil de medir en este caso, como ya hemos visto en otras ocasiones.
Finalmente, no prosperó. La propuesta implicaba que el robot sería el titular de un patrimonio, nos explica Rodríguez de las Heras, y que con él se pagarían los daños que el propio robot generara. “¿Qué ocurre cuando es un delito? ¿Necesita un robot un tutor que administre su patrimonio? ¿Se puede defender ante un juez? Eran muchos más los problemas que las ventajas de la posible solución”, afirma.
Fernando Miró-Llinares, que participa en las conversaciones que tienen lugar en el seno de la Asociación Internacional de Derecho Penal, comenta a Maldita.es que también se estudia “no tener en cuenta determinados diseños” a nivel algorítmico. “Pasa con ámbitos de riesgo: no te castigan solo por causar una muerte estando ebrio, sino por conducir bajo los efectos del alcohol, es la anticipación. Cuando empiece a haber conciencia de que hay determinados robots y programas que conllevan riesgos, el mal diseño de estos algoritmos o máquinas podrá castigarse”, señala.
Tampoco descarta que en un futuro se categoricen nuevos tipos de delitos adaptados a las capacidades de las tecnologías que se vayan creando: “La revolución genética trajo la prohibición de la manipulación genética o la creación de clones. Puede ser que en un futuro se incluyan delitos relacionados con el diseño de los algoritmos”.
¿Es fiable la inteligencia artificial que se usa para predecir la salud de la gente a través de lo que publican en redes sociales?
Esto es algo que se hace, sí. Nuestros perfiles en redes sociales se analizan habitualmente con diferentes objetivos. Es el caso de estudios que usan programas basados en inteligencia artificial para tratar de predecir si una persona está deprimida, tiene tendencias suicidas o puede llegar a desarrollar una enfermedad como el alzheimer. Como lo lees: programas informáticos que ‘leen’ lo que publicamos en Facebook o Instagram y consideran si corremos el riesgo de entrar en un estado depresivo. Ahora bien, ¿hasta qué punto son fiables y cómo se usan hoy en día?
Lo primero es explicar cómo funcionan, ya que cumplen un objetivo muy específico, pero a la vez utilizan los mismos métodos que cualquier otro sistema de inteligencia artificial que analiza textos: en la Maldita Twitchería hemos entrado a fondo en este tema. “El funcionamiento del sistema es como cualquier otra tarea de clasificación de textos o tarea en la que, dado un texto, se trata de asignarle una clase o categoría. En nuestro caso, tenemos como entrada al sistema los textos escritos por un usuario en una red social, y tenemos que asignarle una etiqueta del tipo ‘con riesgo de suicidio’ o ‘sin riesgo de suicidio”, resume a Maldita.es Laura Plaza, profesora titular y miembro del grupo de procesamiento de lenguaje natural (PNL) de la UNED.
Plaza incide en que “los ejemplos deben ser lo más parecido posible a los textos finales con los que trabajará el sistema”. O sea, que a estos sistemas no se les muestran notas de suicidio o textos escritos por una persona que sufre depresión, sino publicaciones en redes sociales que una persona previamente ha marcado como un posible caso de riesgo o no. “Algunos estudios acuden a redes de pacientes de depresión, ansiedad y otros problemas mentales, y toman de ahí conversaciones entre los distintos usuarios”, señala la especialista. Como ejemplo, pone la plataforma Reddit, “una fuente interesante” con “grupos específicos también de problemas mentales”.
“También los historiales clínicos electrónicos son otra fuente de datos súper importante para el procesamiento de lenguaje natural”, añade Rui He, doctorando en el Grammar Cognition Lab de la Universidad Pompeu Fabra.
En el caso de una situación tan delicada como el suicidio, Plaza explica que “se suele contar con la colaboración de expertos en enfermedades mentales para que etiqueten los textos extraídos según su valoración sobre si el usuario que los escribe puede o no llegar a cometer suicidio”. O sea, que en realidad todo pasa por el filtro de una persona especialista que valora si puede haber una tentativa o no. No es tan fácil conseguir ejemplos reales de publicaciones de personas que han intentado suicidarse o se han suicidado para estos casos o, como mínimo, personas diagnosticadas con depresión, por ejemplo, para participar en un estudio.
¿Y cómo se sabe qué ejemplos o qué datos son los que hay que buscar? Rui He detalla a Maldita.es que lo que se suele buscar son “señales lingüísticas” que estén presentes en los textos: “Palabras emocionales como ‘bueno’, ‘amor’, ‘odio’, ‘asqueroso’ serán muy importantes, igual que los emojis”, explica.
Lourdes Araujo, catedrática de universidad en el área de conocimiento de Lenguajes y Sistemas Informáticos, añade también “aspectos como un mayor uso de pronombres en primera persona, de términos relacionados con algún problema (peso o comidas en el caso de anorexia, por ejemplo), mayor o menor cantidad de exclamaciones o emoticonos”, como señales que suelen detectar este tipo de sistemas.
“La precisión de las predicciones depende de la calidad y de la cantidad de los datos. Los posibles sesgos en los datos (por ejemplo que se hayan entrenado con datos de personas jóvenes, que no representan bien a personas de edad) son un aspecto que es imprescindible considerar”, recuerda Araujo.
Lo vemos con este estudio realizado con publicaciones en español: para entrenar al sistema que analizaba los posts, se usaron como referencia 513 tuits clasificados como posibles casos de suicidio y 346 frases evaluadas por médicos clínicos. En él admiten la dificultad de acceder a informes médicos y también señalan algunas limitaciones: la falta de representación que hay en Twitter para entrenar un modelo informático, ya que al fin y al cabo la mayoría de usuarios son hombres blancos de edad media.
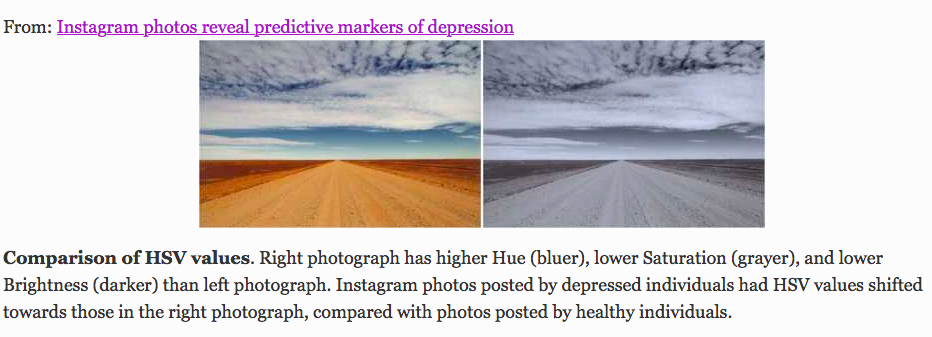
Otro estudio se basaba en el análisis de imágenes, en vez de texto, y concluía que las fotos publicadas en Instagram por personas con depresión “eran más proclives a ser más azuladas, grisáceas y oscuras, y a recibir menos likes”: “Los usuarios de Instagram con depresión de nuestra muestra tenían una mayor preferencia por filtrar todos los colores de las fotos y mostraban aversión a las fotos iluminadas artificialmente”.
Incluso Facebook lleva experimentando desde 2017 con programas de inteligencia artificial dedicados a la “prevención del suicidio”: “Nuestra tecnología utiliza señales, como frases en publicaciones y comentarios que muestran preocupación por parte de amigos y familiares, para identificar posible contenido relacionado con el suicidio y la autolesión. En general, las publicaciones que suelen indicar un riesgo inminente de lesión, incluyen comentarios como ‘Dime dónde estás’ o ‘¿Alguien sabe algo de él/ella?’”. Sin embargo, aclaran que “los algoritmos no desempeñan ninguna función clínica o de diagnóstico y no pueden diagnosticar ni tratar ninguna enfermedad mental o de otro tipo”, sino que lo único que hacen es buscar estas señales para reducir su visibilidad, eliminarlos de la plataforma o, en todo caso, que lo revise el personal que asiste a los usuarios.
Piensa que estos programas informáticos no se desarrollan para ‘hacer de médico’: una máquina no nos debería dar un diagnóstico médico. Su labor es, por tanto, crear una forma de hacer un escaneo más o menos rápido por las redes sociales y alertar a las personas involucradas de que alguien puede sufrir algún problema de salud mental, por lo que, según los especialistas consultados, no deberían usarse sin supervisión humana.
“Estos sistemas no vienen a suplantar al experto: el riesgo de suicidio no es una enfermedad ni se puede diagnosticar, van a dar la voz de alarma, por ejemplo, a un padre si las conversaciones de su hijo adolescente pueden indicar que piensa en el suicidio. El paso posterior sí es acudir a un profesional de la salud mental, por supuesto”, remarca Laura Plaza.
La gran pregunta: ¿son fiables, en ese caso, o no? ¿Y cómo se usan a día de hoy? Una revisión de 35 estudios sobre inteligencia artificial para detectar signos de suicidio en posts en redes sociales asegura que el uso de estas técnicas “ayudará en la predicción y prevención del suicidio”. Otro estudio sobre casos específicos de adolescentes afirma que son útiles para detectar cuándo puede una persona joven estar sufriendo amenazas o bullying en sus redes y que eso modifique el tono de sus publicaciones.
La conclusión de los especialistas contactados por Maldita.es es que los sistemas pueden ser más o menos fiables para detectar los primeros signos de una depresión por ejemplo, pero que siempre van a ser un complemento al diagnóstico médico, nunca una sustitución.
“La precisión y cobertura de estos sistemas es elevada (puede que mayor que los humanos, pero no creo que podamos afirmarlo con rotundidad)”, afirma Plaza. “A día de hoy no está aceptado que puedan utilizarse sin supervisión. Pero podrían ser una importante fuente de información adicional para ayudar a hacer diagnósticos”, coincide Araujo. Según Rui He, los algoritmos de machine learning están “lejos de ser suficientemente inteligentes para reemplazar a los profesionales”.
Estas especialistas también coinciden en que este tipo de inteligencia artificial se usa por el momento en un plano teórico y no conocen casos en los que se haya estandarizado su uso, por ejemplo, en un hospital o un centro médico. Aun así, hay empresas como IBM que sí venden soluciones de tecnología basada en inteligencia artificial a un nivel comercial, por ejemplo chatbots y programas para analizar datos.
Además de esta explicación tecnológica, te animamos a leer la información que dan los compañeros de Maldita Ciencia sobre el suicidio y la depresión.
Y para terminar...
No somos técnicos o ingenieros pero contamos con mucha ayuda de personas que son expertas en su campo para resolver vuestras dudas. Tampoco podemos deciros qué servicio usar o dejar de usar, solo os informamos para que luego decidáis cuál queréis usar y cómo. Porque definitivamente, juntos y juntas es más difícil que nos la cuelen.
Si tenéis cualquier duda sobre esta información o cualquier otra relacionada con la manera de la que te relacionas con todo lo digital, háznosla llegar: