Entender a las máquinas (y que las máquinas nos entiendan a nosotros) es uno de los grandes retos de la investigación tecnológica moderna. Tenemos muchísimos ejemplos de los últimos avances: Alexa o Siri procesan cada vez más tipos de preguntas, la traducción automática de textos a varios idiomas se ha vuelto bastante precisa y los subtítulos generados automáticamente por YouTube se adaptan cada vez mejor a lo que dicen los protagonistas del vídeo, aunque siga siendo difícil que lo entiendan todo. La disciplina que estudia esta comunicación humano-máquina es el procesamiento de lenguajes naturales, nuestro último protagonista en la Twitchería tecnológica.
Un futuro con Siri o Alexa iniciando "proactivamente" las conversaciones
¿Qué proceso hay detrás de una pregunta a Siri? Nos lo explicaron Zoraida Callejas y David Griol, profesores del Departamento de Lenguajes y Sistemas Informáticos de la UGR. En la comunicación oral con la máquina el sistema debe seguir varios pasos: transformar nuestro audio en una cadena de texto, procesar su significado, identificar la información que le estamos reclamando, redactar una respuesta y transformarla en voz. El futuro pasa por crear "sistemas proactivos" que entiendan el contexto de las conversaciones e incluso que la propia máquina pueda ser la que inicia las conversaciones si detectan alguna duda o necesidad, según añadieron los expertos.
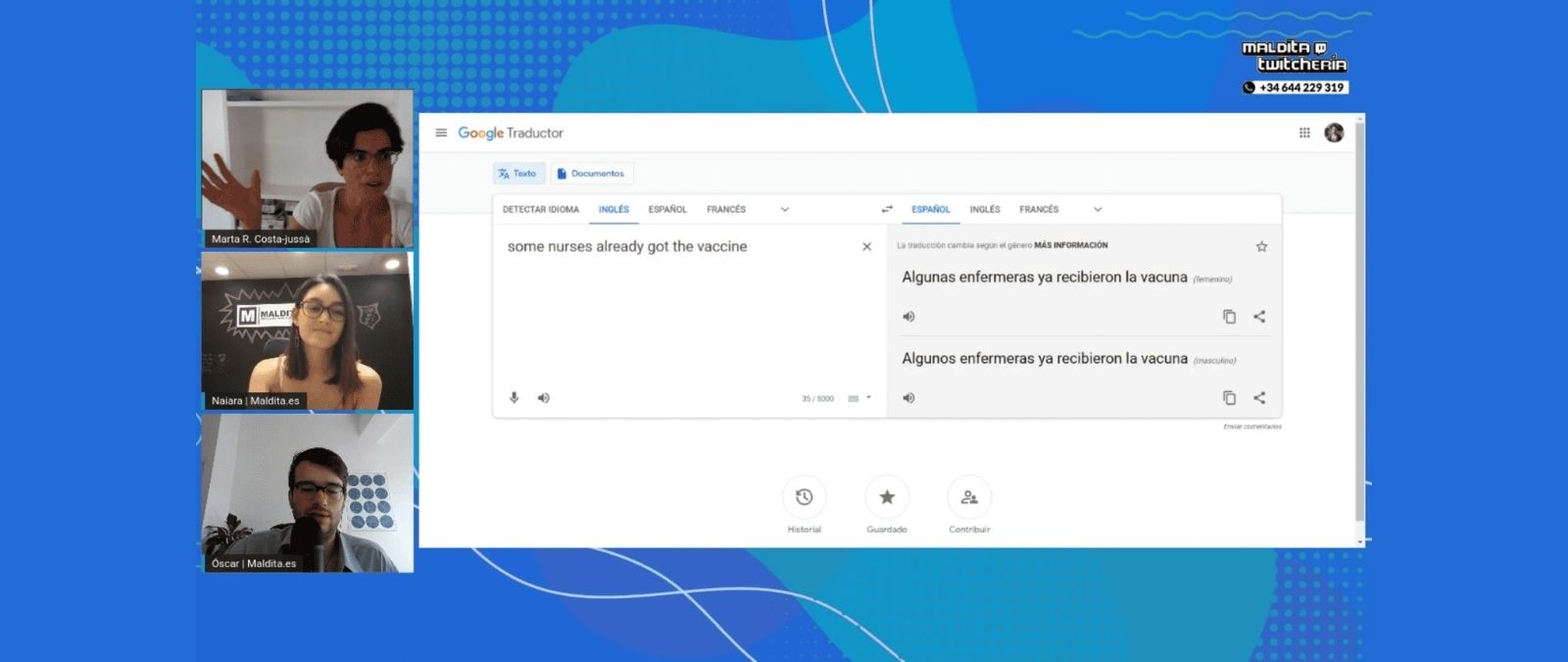
Las traducciones automáticas y su mejora en base a "cantidades masivas de datos"
No es lo mismo hacer traducciones de calidad en idiomas hablados mundialmente que en lenguas minoritarias. Como en el resto de algoritmos, la cantidad de datos es clave para entrenar a las máquinas y, a mayor cantidad de ejemplos, más calidad tendremos en la interpretación de los textos. Así nos lo explicó Marta R. Costa-jussà, investigadora de Traducción Automática en la Universidad Politécnica de Barcelona: "El aprendizaje profundo utiliza cantidades masivas de datos. Pero, para lo que nosotros necesitamos cuatro ejemplos, el algoritmo necesita millones. El reto es que las máquinas aprendan con menos datos, ya que actualmente supone un gasto computacional y energético muy alto".
"La máquina puede detectar palabras y encontrarles el sentido, pero el sarcasmo todavía es muy difícil que lo entienda"
Iria da Cunha Fanego, doctora en Lingüística Aplicada e investigadora de Lingüística Computacional en la UNED, acudió a la Twitchería para hablar de los retos del procesamiento de lenguaje natural, sobre todo en su parte escrita. Para que nos entendamos, la máquina puede procesar varias capas de un texto humano: léxico, morfológico, sintáctico, discursivo... Sin embargo, aún quedan muchos aspectos para mejorar la interpretación que estas máquinas hacen del texto. "La máquina puede detectar palabras y encontrarles el sentido, pero el sarcasmo todavía es muy difícil que lo entienda", añadió la experta como ejemplo. Da Cunha, que además es una de las creadoras del proyecto arText, también hizo hincapié en otra de sus líneas de trabajo: la redacción de textos en lenguaje claro. Esta es "una alternativa sencilla para que la ciudadanía entienda mejor" los documentos administrativos o especialmente técnicos.
"Esta tecnología se confunde con magia, y eso es un error"
¿Qué aplicaciones tienen estos sistemas de lenguaje automatizado en la empresa y en la vida real de los usuarios? Nos lo explicó Carlos Sanguesa, CEO de Pixelabs, una empresa especializada en modelos de lenguaje natural, inteligencia artificial y big data. Bajo su punto de vista, en muchas ocasiones este tipo de tecnología "se confunde con magia, y eso es un error". Para Sanguesa es importante identificar "casos de usos realistas", como pueden ser los sistemas objetivos de traducción e interpretación de los que hablaron las invitadas anteriores. "Pero en toda esa parte de la comprensión humana estamos aún un poquito lejos y hay que ser cautos", explicó.