
¡Buenas, malditas y malditos! Un martes más nos pasamos por aquí para traeros una nueva entrega de nuestro consultorio tecnológico, que ya va camino de su edición número 100. Hoy os contamos cómo en el inicio de Internet se compraban dominios con nombres clave para especular con ellos, cómo se gestionan los datos personales en sistemas inteligentes de gestión de residuos y qué podemos hacer para evitar que se escaneen nuestros datos para fines que no hemos consentido si nuestros datos personales están publicados en una web.
Sabemos que con cada día que pasa, nos van surgiendo más y más preguntas sobre el mundo digital y que aquí estamos para resolverlas. Así que podéis mandarnos vuestras dudas a través de este formulario, mandando un correo a [email protected], con un mensaje a nuestro Facebook, a nuestro Twitter o a nuestro chatbot de WhatsApp (+34 644 229 319).
¿Es verdad que en los inicios de Internet (web 2.0) la gente compraba dominios de grandes empresas como Coca Cola para poder venderlas luego a precios altos?
Los dominios son los encargados de llevarnos a la dirección IP del servidor donde está alojada la página web que queramos visitar. De esta forma, a través de un nombre amigable, fácil de recordar y reconocible, evitamos tener que memorizar miles de números para poder visitar un contenido. De ahí a que tener un dominio que se asocie con tu marca sea importante. El de Maldita.es es el que le da nombre a nuestro medio, por ejemplo.
Anteriormente nos preguntasteis qué pasaría si una persona comprase un dominio que contenga nuestro nombre. Esta vez, nos preguntáis por la especulación y compra-venta con los nombres en los inicios de Internet.
“Allá por los años 90, la aparición y crecimiento de las ‘.com’ atrajo la atención de aquellos que vieron el valor potencial de los nombres de dominio, y en ese momento muchos de los nombres genéricos más valiosos comenzaron a ser registrados”, comienza a explicar a Maldita.es Alberto Amado, ingeniero informático y maldito que nos ha prestado sus superpoderes.
Se trataban de palabras clave como “vacaciones”, “hoteles” o “seguros”, principalmente en inglés. Tal y como recopilan en este blog de Telefónica sobre las ventas de dominios más altas, los nombres que ocupan los primeros puestos del ránking son “insurance.com” (en español podríamos traducirlo como seguros.com), que se vendió en 2010 por 35,6 millones de dólares; “vacationrentals.com” (alquilerdevacaciones.com), que lo hizo por 35 millones de dólares; o “internet.com”, por 18 millones de dólares.
Nos da más ejemplos David Carrero, inversor y cofundador de Stackscale, que cuenta que “en su momento, registramos dominios de palabras o cosas que pudiesen tener interés para desarrollar algún proyecto si no llegaba ningún interesado en comprarlo, como recursosgratis.com o programacion.com”. “Empezamos en 1998 con los .com, y luego hicimos lo mismo con los .es en 2005”, añade Carrero.
Además de inversores particulares, también existen o existieron empresas especializadas en comprar una gran cantidad de nombres de dominio con palabras clave. Por ejemplo, World Accelerator es una empresa fundada por Gary Miller, un empresario estadounidense que desde los inicios de la red se hizo con miles de dominios con palabras específicas como “england.com” o “world.com”. Ahora, con los que no ha vendido, se dedica a alquilarlos o prestarlos temporalmente a empresas interesadas en ese dominio a cambio de un porcentaje de los derechos de propiedad.
Nuestro maldito e ingeniero informático Alberto Amado comenta que “el negocio es y era sencillo: o bien se permanece alerta para hacerse con los dominios más jugosos si sus dueños se deshacían de ellos o se descuidaban de renovarlo, o bien se centraban en comprar dominios libres que no han sido registrados y esperar a que alguna empresa o particular estuviese interesado y fuese a buscarlo”. “Lo peor en estos casos es que estos dominios nunca lleguen a ser utilizados y se mantengan registrados y sin ser usados”, añade.
¿Pasaba lo mismo con los nombres relacionados con empresas? Aquí la situación cambia en función de si las marcas estaban registradas. En el portal especializado DNDisputes (“disputas de nombres de dominio”, por su traducción del inglés), recogen todos los casos de reclamaciones de estos dominios ante la Organización Internacional de Propiedad Intelectual. Es decir, empresas que reclaman a la autoridad que les sean transferidos estos dominios que consideran que sólo ellos pueden poseerlos por tener registrada la marca.
“La ciberocupación consiste en el registro, el tráfico o el uso de un nombre de dominio de internet con la intención de mala fe de beneficiarse de la buena voluntad de una marca comercial perteneciente a otra persona”, aclara Amado, “tal y como se recogió en la Política uniforme de resolución de disputas de nombres de dominio, creada en 1999 por la ICANN, el organismo internacional de nombres de dominio, para tratar estos asuntos, y que ha resuelto más de 50.000 casos desde entonces”.
Por ejemplo, la empresa que más dominios ha reclamado ha sido Lego, con un total de 1.582, que usaban nombres como legohub.store, lego.tech o masquelegos.com. Eso sí, ello no implica que todos los que reclame le sean transferidos por los derechos de propiedad. Esta empresa, por ejemplo, no ha logrado ganar el 30% de los casos que ha comenzado. En la misma lista encontramos otras empresas conocidas, como Instagram o Meta, que suelen reclamar cualquier dominio que contenga el nombre de algunos de sus productos o pueda llevar a la confusión, como verify-instagram.com o instagrarn.net.
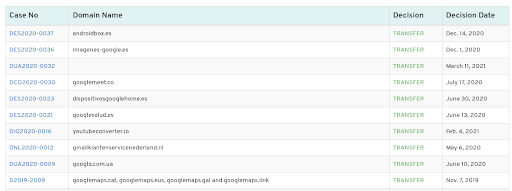
Es decir, que en el caso de nombres relacionados con marcas registradas o empresas, el negocio es bastante menor porque la autoridad competente suele ordenar, si así lo considera, la transferencia del dominio, sin que exista un pago a quien registró el dominio para obtener ganancias.
Existen dos casos paradigmáticos. El primero, el del dominio mtv.com, que registró uno de los empleados del canal de televisión, Adam Curry. Según su versión, se lo había comunicado antes a sus superiores, que no se opusieron. Eso sí, en cuanto la compañía se dio cuenta del potencial de Internet, reclamó y obtuvo el dominio a cambio de pagar una suma que nunca se ha revelado.
El otro fue mcdonalds.com, registrado por Joshua Quitter, un periodista que incluso llegó a acudir a las oficinas centrales de la cadena de comida rápida antes de comprarlo para advertirles de que podía adquirirlo, “igual que podría hacerlo Burger King si quisiese [su principal rival en el sector]”. McDonalds, al igual que MTV, tampoco vio interés en ese dominio y no fue hasta años más tarde cuando se lanzó a por él, a cambio de suministrar ordenadores al colegio donde estudió Quitter.
“Hoy en día este mercado está lejos de ser lo que fue, aunque siguen existiendo oportunidades para dominios .com y .es entre otros”, aclara Carrero. “Con la llegada de multitud de extensiones como .tech, .biz, o .news, se ha relajado esta compra-venta”, añade el cofundador de Stackscale.
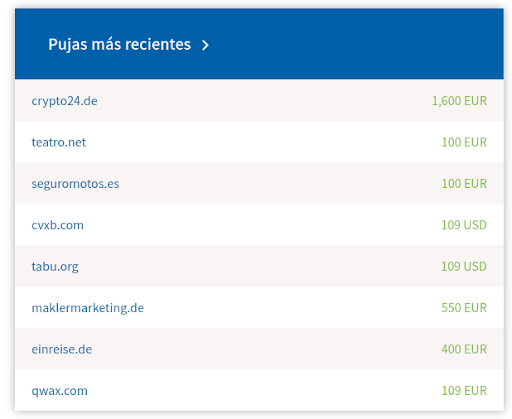
A pesar que esta compra-venta de dominios ha ido decayendo con respecto al boom que tuvieron al principio, todavía encontramos subastas y compras de nombres característicos. Por ejemplo, en Sedo, un portal para registrar dominios, se realizan constantemente subastas. En el momento de redactar esta pieza, los usuarios están pujando por nombres como “teatro.net”, “seguromotos.es” o “crypto24.com”, con ofertas entre los 100€ y los 1.600€.
¿Es legal que una mancomunidad instale un sistema de basuras inteligente que monitoriza qué y cuánto recicla cada vivienda? ¿Sin hacer firmar nada a nadie y sin informar debidamente?
Las llamadas smart cities son ciudades en las que se utiliza la tecnología para recoger diversos datos sobre el funcionamiento del día a día y gestionar, de forma conectada y eficiente, los recursos y aspectos socioeconómicos, como puede ser la gestión del tráfico o la del agua.
Una de las ramas de las ‘ciudades inteligentes’ es la gestión de los residuos. Algunos ayuntamientos y mancomunidades están lanzando estos programas para aumentar la eficacia y la eficiencia en el reciclaje y en la recogida de basura. En algunas ciudades tienen o han puesto en marcha proyectos piloto para hacer “inteligentes’ estos procesos: saber el estado en el que se encuentra cada contenedor, hacer una ruta de recogida en base a esto, modernizar y adaptar la flota de camiones, obtener información sobre el estado del servicio en tiempo real…
En Barcelona, el proyecto incluye un sistema de identificación del usuario para poder bonificar a los ciudadanos vía impuestos según el volumen de residuos que se reciclen, para así “incentivar” la separación de restos. Pero, ¿qué encaje legal tiene este sistema? ¿Es legal que se implemente un sistema de basuras inteligente, ya sea a nivel municipal o de comunidad de propietarios, sin obtener el consentimiento? ¿La información sobre lo que reciclamos es un dato personal? Varias preguntas que nos habéis hecho llegar, así que vamos a verlas.
La respuesta es que todo depende de los datos recogidos y la especificidad en los mismos. Existen sistemas que no recolectan información acerca del reciclaje que realiza cada vivienda. Desde Ecoembes comentan a Maldita.es que “existen proyectos en los que no se ceden los datos, sino que utilizan datos disponibles al público, como la población”.
Por ejemplo, aseguran que en Ecoembes han realizado un proyecto piloto con varios ayuntamientos para gestionar los residuos “de manera inteligente”, llamado Smartwaste, que se basa en “cruzar datos propios del ayuntamiento (ubicación de contenedores, cantidades de residuos que llegan, etc.) con datos públicos (población del INE) para hacer estimaciones que ayuden a mejorar el servicio que se presta a los ciudadanos, sin que se traten o almacenen sus datos personales”, explican desde la organización.
Nelia Álvarez, abogada experta en protección de datos, aclara que “si no requiere identificar a la persona que deposita sus residuos, y simplemente el sistema se utiliza para gestionar los residuos y no para ofrecer bonificaciones a ciudadanos, por ejemplo, no sería de aplicación la normativa de protección de datos personales”. Al no registrar quién recicla y en qué cantidad lo hace, no se estaría recogiendo ningún dato identificativo.
En proyectos como el de Barcelona, cuya intención es registrar los hábitos de reciclaje de los vecinos para ofrecer bonificaciones fiscales, ¿cómo encaja en la legislación sobre protección de datos? “En la medida en que la información relacionada con los hábitos de reciclaje o sobre los residuos desechados se vincule con una persona identificada o identificable se convierte en dato personal”, comenta la abogada. “Incluso aunque no se relacione directamente con un nombre o apellidos, basta con que contenga información que permita inferir la identidad de una persona, como su domicilio”, añade Álvarez.
Con ella coincide Maitane Valdecantos, abogada especializada en derecho digital y propiedad intelectual: “Para concretar si el ayuntamiento va a realizar un tratamiento de datos personales de sus ciudadanos relacionados con el reciclaje de residuos, debemos atender al grado de identificación inicial que se realizaría de cada persona y valorar si la actividad de reciclaje realizada puede ser entendida como un dato personal”. Quizás la bolsa de basura que tiramos no lleva nuestro nombre, pero, ¿y si estuviera asociada a mi casa y, por tanto, a mi dirección?
También se tendría que evaluar el tipo de datos que se van a recoger y si su uso es proporcional “para no recoger más datos de lo estrictamente necesario para lo que se quiera conseguir”, especifica Álvarez. “Luego, el consentimiento a participar en estos proyectos tiene que ser libre, por lo que no puede venir impuesta la medida por una norma ni causar perjuicios a la persona que se oponga a este tratamiento de sus datos”, comenta. Es decir, que deberíamos tener una alternativa si no queremos que nuestra información personal se usase vinculada a un sistema así.
Nos pone un ejemplo Valdecantos: “Si para poder utilizar el sistema de reciclaje es necesario estar registrado en una determinada ‘app’ en la que deberemos aportar una serie de información (nuestro nombre, dirección, etc.), estaremos ante una actividad sujeta a la normativa en materia de protección de datos, en la que se podría vincular el porcentaje de reciclaje realizado por cada individuo con una persona identificada, pudiendo llegar a conocerse las veces que hemos reciclado vidrio a la semana”.
¡Ajá! Ahí sí que entran en escena las normas de protección de datos e incluso un posible perfilado de los vecinos. “La normativa de protección de datos prevé que la elaboración de perfiles deba contar con una base jurídica de tratamiento muy clara y deberá informarse al ciudadano de la existencia de la elaboración de perfiles, de las consecuencias de dicha elaboración, de si están obligados a facilitar sus datos y de las consecuencias en caso de que no lo hicieran”, concluye Valdecantos.
En caso de que no se proporcionara esta información pero se tiene sospechas de que puede existir esta clasificación por parte de la comunidad, se podría solicita información, recabar pruebas y acudir a la Agencia Española de Protección de Datos.
Si necesariamente tengo que publicar mis datos personales en una página web (porque soy autónoma, por ejemplo), ¿hay algo que pueda hacer para evitar que se escaneen mis datos y se usen para otros fines que no he consentido?
Por muy cuidadosos que queramos ser a la hora de exponer nuestros datos personales en Internet, hay veces que no podemos evitar hacerlos públicos. Por ejemplo, al ser autónomo y propietario de una empresa y verse obligado a publicar en su página web ciertos datos de contacto, aunque sean referentes a la compañía. Es el caso de la autora de una de las preguntas que incluye el consultorio tecnológico de esta semana, así que vamos a ver qué pasos podemos seguir para mitigar el impacto que puede causar esa exposición de información personal.
Su preocupación es que el tener esos datos públicos en una página web llevase a que se usaran con fines ilegítimos o para los que no se hubiese dado autorización. Por ejemplo, usar los datos de contacto para incluirlos en paquetes comerciales, para cometer fraude o incluso para suplantar su identidad.
La recogida de datos podría hacerse de dos maneras: manualmente (es decir, que una persona de forma proactiva registrase y usase los datos) o de forma automatizada. Esta segunda opción consistiría en el scrapeo de información de diferentes fuentes en Internet, como bases de datos públicas (por ejemplo, el BOE), redes sociales o páginas web. Se lleva a cabo mediante bots: programas informáticos automatizados con distintos objetivos, como el escanear una web en busca de información. A este tipo de programas también se les conoce en el mundo informático como ‘arañas’.
Frente a la recogida indiscriminada de datos que colgamos en páginas web por distintos motivos, hay varios pasos que podemos seguir para protegerlos. De menor a mayor dificultad para el usuario, podríamos ordenarlos de la siguiente manera: limitar en la medida de lo posible la cantidad y la categoría de los datos que publicamos; introducir un intermediario como un ‘CAPTCHA’ en la página en la que se alojan los datos; o instalar lo que se conoce como un firewall de aplicación web (Web Application Firewall o WAF, por sus siglas en inglés).
Desde el punto de vista legal, es cierto que hay ciertos datos que debemos incluir en una página web si ofrecemos un producto o un servicio a través de ella. La información clave que debe mostrar una página web viene marcada por la Ley de Servicios de la Sociedad de la Información, tal y como nos explica Vanesa Alarcón, abogada especializada en derecho digital en Ecija.
"Nombre o denominación social, residencia o domicilio; el correo electrónico, los datos registrales de la sociedad mercantil (cuando se tenga)", enumera. También, si se busca establecer canales de comunicación directa, se pueden incluir teléfonos de contacto, canales o redes sociales de atención al cliente, entre otras. "También es preciso el número de identificación fiscal, y si la por la actividad de la Web lo requiere, los precios del producto o servicios (indicando si incluye o no los impuestos, o los gastos de envío), y los códigos de conductas, a los que se encuentre la entidad adherida", añade. A esto habría que añadir, cuando proceda, un número de colegiado según la profesión desempeñada.
¿Hay alguna forma de minimizar la exposición de estos datos? Según explica a Maldita.es Alarcón, "podemos indicar, por ejemplo, el nombre en el apartado de datos de contacto o de titularidad de la página nuestro nombre comercial, utilizando la fórmula 'en adelante, NOMBRE COMERCIAL' con lo cual, los nombres, no aparecerán repetidos en tantas ocasiones". Otra fórmula, indica, consistiría en considerar añadir un domicilio de coworking o incluso un apartado de correos para evitar exponer los datos del domicilio particular.
Una vez sabemos qué datos podemos incluir y cuáles no, pasamos al siguiente nivel de protección, que consiste en establecer una especie de barrera entre la página web y el usuario que la visita. ¿Por ejemplo? A través de un test CAPTCHA. Como hemos contado ya en Maldita.es, un CAPTCHA es una forma de autentificación para que los proveedores de servicios comprueben que no somos bots. Se presentan en forma de puzles o pequeños rompecabezas que tenemos que resolver para acceder a una web.
Estas pruebas se diseñan precisamente para evitar que haya programas automatizados accediendo continuamente a las webs, por lo que puede actuar como barrera entre distintos apartados de una misma página. En nuestro caso, nos interesaría esconder tras uno de estos tests los datos personales que no queremos que sean scrapeados.
Marc Almeida, analista de datos, explica a Maldita.es que esto supondría “poner una pequeña cerradura” al sitio donde se alojan nuestros datos. Al final, destaca, se trata de hacerlos públicos pero “nos aseguramos en la medida de lo posible que sea un humano quien los vea”.
Si en vez de por uno de estos puzles queremos optar por algo más sencillo, el analista recomienda instalar en nuestra página web “un botón que genere o expanda los datos en el momento en el que se hace clic”. Esto evitaría que la información personal esté siempre en abierto en la web, y que solo se hicieran visibles para el usuario cuando este desplegase la ventana que los contiene. Este tipo de trabas también pueden frenar a los bots.
El tercer y último paso que podríamos seguir requiere de conocimientos técnicos o, como mínimo, recurrir a una persona profesional que los tenga. “Evitar el scraping es complicado, sobre todo si es en una sección específica, pero se puede probar el uso de CSS para mostrar esos datos o el más efectivo: usar un firewall de aplicaciones tipo web (WAF)”, nos recomienda Ana Isabel Corral, especialista en ciberinteligencia y seguridad informática.
¿Qué es un CSS? Son las siglas del término inglés Cascading Style Sheets (u “hojas de estilo en cascada” en español). Es un tipo de código informático usado para personalizar en mayor o menor grado la apariencia y las funciones de una web. De esta manera, señala Corral, se podría modificar el sitio web para que los datos no fueran tan expuestos en la web o incluso no quedaran reflejados.
Vale, ¿y un WAF? Corral explica que esta tecnología bloquea las “llamadas” injustificadas que se hacen a una página web, es decir, cuando tecleamos una dirección web para acceder a ella. “Lo que hacen [los WAF] es pelear contra los bots. Identifican la conexión, el acceso a la web y, dentro de si lo es un bot o no y si saben si es malicioso o no lo dejan pasar”, añade Almeida. ¿Qué bots son esos? Los de Google, las arañas de rastreo son, según este analista, “más o menos buenos”. Algunas de las empresas que ofrecen estos servicios son Cloudflare o Transparent CDN, señala el analista.
¿Cómo se hace esa identificación? También nos lo explica: “Un bot, si lo que busca son los datos del usuario, lo que va a intentar hacer es abrir todas las páginas, realizar x peticiones, a ver si encuentra el apartado de ‘about’ o el ‘acerca de’ y hacer varias peticiones en muy poco tiempo. En base a eso, considera si es humano o no”.
De modo que, dependiendo de los recursos y la familiaridad del usuario con el desarrollo web, podrían usarse diferentes métodos para ocultar estos datos: directamente limitando la información publicada, ocultándola tras test CAPTCHA y otras funcionalidades que los escondan de las páginas principales, o contratando un servicio de WAF que bloquee los accesos indebidos. Para esta última opción también se puede acudir a un especialista.
No os vayáis sin este recordatorio
No somos técnicos o ingenieros pero contamos con mucha ayuda de personas que son expertas en su campo para resolver vuestras dudas. Tampoco podemos deciros qué servicio usar o dejar de usar, solo os informamos para que luego decidáis cuál queréis usar y cómo. Porque definitivamente, juntos y juntas es más difícil que nos la cuelen.
Si tenéis cualquier duda sobre esta información o cualquier otra relacionada con la manera de la que te relacionas con todo lo digital, háznosla llegar:
En este artículo ha colaborado con sus superpoderes el maldito Alberto Amado, ingeniero informático.
Gracias a vuestros superpoderes, conocimientos y experiencia podemos luchar más y mejor contra la mentira. La comunidad de Maldita.es sois imprescindibles para parar la desinformación. Ayúdanos en esta batalla: mándanos los bulos que te lleguen a nuestro servicio de Whatsapp, préstanos tus superpoderes, difunde nuestros desmentidos y hazte Embajador.