El análisis de datos es más complejo de lo que parece y en ocasiones puede llevar a engaño. Desde que comenzó la pandemia de COVID-19, se publican diariamente datos sobre contagios, hospitalizaciones y muertes; y ahora también sobre la efectividad de las distintas vacunas. Y, aunque las vacunas contra la COVID-19 han demostrado su eficacia y efectividad, si analizamos los datos de forma errónea podemos llegar a conclusiones equivocadas. Un ejemplo de las falacias en las que podemos incurrir es la paradoja de Simpson, que recibe su nombre de un artículo publicado por el estadístico Edward Hugh Simpson en 1951 y fue observada anteriormente por los estadísticos Karl Pearson (en 1899) y Udny Yule (en 1903).
¿Qué es la paradoja de Simpson?
La paradoja de Simpson ocurre cuando al analizar grupos de datos de forma conjunta se producen resultados diferentes o contrarios que al analizarlos por subgrupos. Esto ocurre porque existe una (o más de una) variable confusora, es decir, un factor oculto que tiene mucho peso dentro de los datos y desequilibra la balanza cuando estos se analizan de forma agregada, llevando a resultados engañosos. Por ello, es necesario dividir los datos en subgrupos para poder analizarlos según las variables de confusión y sin que los resultados nos induzcan a error.
Un ejemplo claro es el de esta infografía que ha publicado el divulgador Influciencia en su cuenta de Instagram**. Si analizamos los datos totales, vemos que un 75% de las personas que fallecieron en accidentes de tráfico llevaba el cinturón de seguridad (110 de 145), llegando a la conclusión (errónea) de que el cinturón de seguridad no es eficaz. Sin embargo, si analizamos los datos por subgrupos, vemos que en los accidentes sin cinturón mueren el 70% de las personas (35 de 50) y en aquellos donde las personas llevaban el cinturón mueren solo el 11% (110 de 950). Es la conclusión contraria a la anterior.
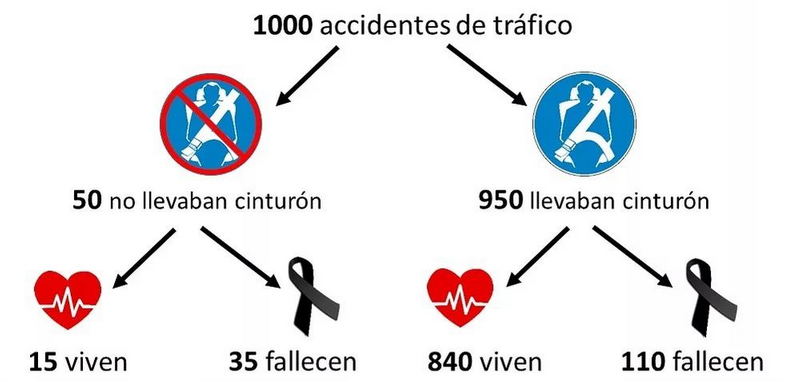
¿Por qué ocurre esto? Porque en el total de accidentes analizados (1000), el grupo de accidentes donde las personas llevaban cinturón es mucho más grande (950) que el de quienes no lo llevaban (50). Por lo tanto, a la hora de analizar los datos de fallecidos de forma conjunta ese subgrupo pesa mucho. De esta forma, en el grupo de fallecidos había muchas más personas con cinturón que sin cinturón, pero no quiere decir que no sea eficaz o que las personas con cinturón en accidentes fallezcan en mayor proporción que las que no lo llevaban*.
Veamos ahora el ejemplo que utiliza Tom Grigg en el blog divulgativo ‘Towards Data Science’. Una empresa de refrescos quiere saber cuál de sus dos nuevos sabores le gusta más al público. Para ello coloca dos puestos en una calle concurrida, uno con refrescos de fresa y el otro con refrescos de melocotón. Desde cada puesto se da a probar el refresco a 1.000 transeúntes y se anota si a la persona le ha gustado el sabor.

De las 1.000 personas que se cruzaron con el puesto de los refrescos de fresa y probaron uno, a 800 les gustó, mientras que las otras 1.000 personas que probaron un refresco de melocotón en el otro puesto, les gustó a 750. Analizando estos datos de forma agregada y simple, parece claro que el refresco de fresa (80%) tiene mayor acogida que el de melocotón (75%). Pero, ¿qué ocurre si tenemos en cuenta otros datos, como, por ejemplo, el género de cada transeúnte?
En este caso, se ve que es el refresco de melocotón, y no el de fresa, el que gusta más tanto los hombres (un 85,7% frente a un 84,4%) como las mujeres (un 50% frente a un 40%). Es la conclusión contraria a la que obtenemos cuando analizamos los datos de forma conjunta: ¿cómo es posible que a la población en general le guste más el refresco de fresa, pero tanto hombres como mujeres por separado prefieran el de melocotón?
En primer lugar hay una variable confusora que está actuando sobre estos datos y es el género. En este caso ficticio, descubrimos que el gusto por un refresco tiene más relación con el género que con el sabor del refresco. Es decir, si a una persona le gusta un refresco, no es tanto por su sabor como por ser hombre o mujer. En concreto, el de fresa gustó a un 84,4% de los hombres, pero solo a un 40% de las mujeres.
Sabiendo que a los hombres les gusta mucho más el sabor fresa que a las mujeres (en este supuesto ficticio), ahora pensemos que por ese puesto pasaron 900 hombres y solo 100 mujeres. Claramente, al analizar los datos totales del puesto con refrescos de fresa pesa mucho el subgrupo de los hombres. Tanto, que llega a superar el porcentaje total del puesto con refrescos de melocotón. Aunque en el puesto con bebida de melocotón los subgrupos de hombres y mujeres están más repartidos, no llegan a compensar este efecto. Esta es la segunda razón por la que se produce la paradoja: los subgrupos tienen tamaños diferentes.
Varios divulgadores han publicado explicaciones de esta paradoja con más ejemplos, reales y ficticios, como hizo el matemático Javier Álvarez Liébana en un hilo en su cuenta de Twitter.
¿Cuándo ocurre esta paradoja con los datos sobre la efectividad de las vacunas contra la COVID-19?
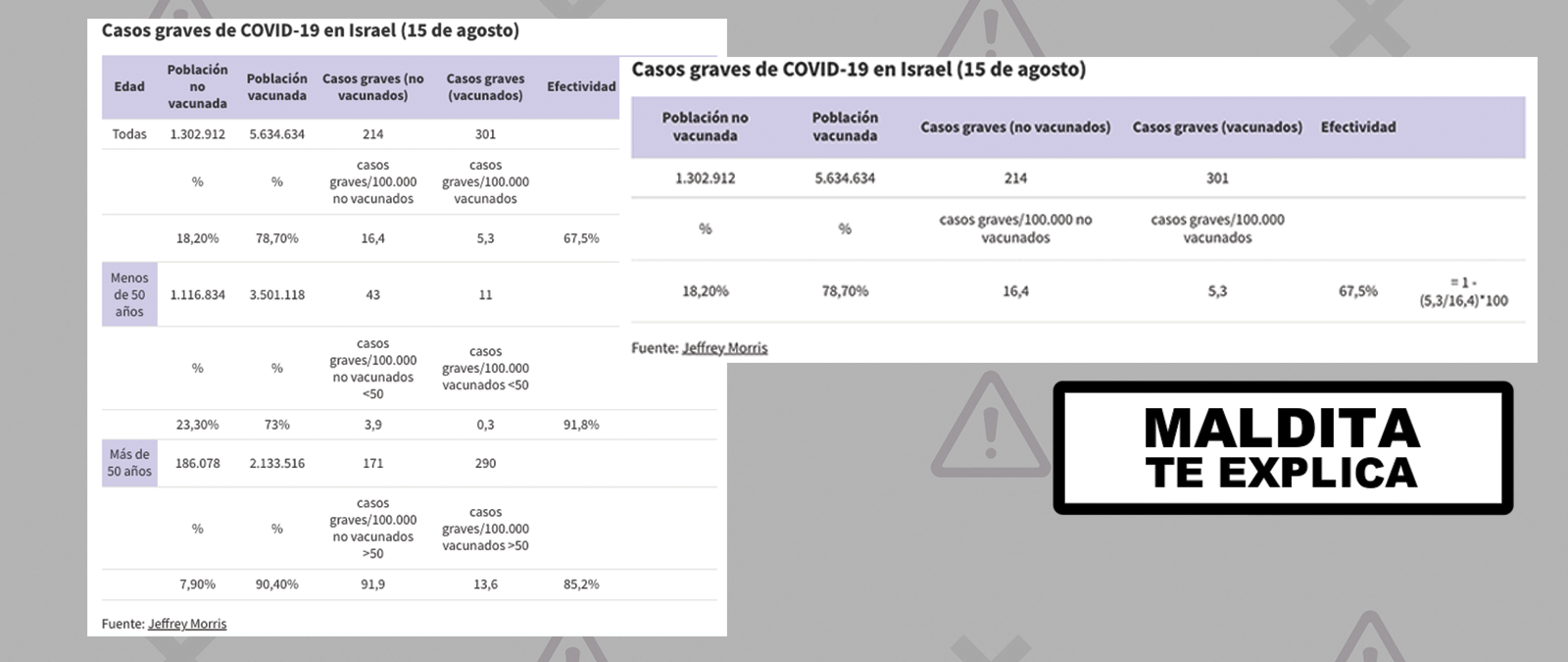
¿Cómo puede afectar esta paradoja cuando hablamos de las vacunas contra la COVID-19? ¿En qué casos puede llevarnos a error? Como explica el analista de Datos Jeffrey Morris, este fenómeno es muy útil para explicar por qué, a pesar de que en agosto en Israel el porcentaje de pacientes hospitalizados por COVID-19 vacunados era superior al de no vacunados, las vacunas seguían siendo efectivas. Un caso que se podría ver repetido en otros lugares del mundo, sobre todo a medida que va avanzando el porcentaje de población vacunada.
Según los datos públicos de Israel que menciona Morris, el 15 de agosto, de los 515 pacientes ingresados por COVID-19 en los hospitales israelíes, 301 (un 58,4%) estaban vacunados con dos dosis de Pfizer. Aquí aparece la paradoja, haciéndonos pensar que las vacunas no son efectivas.
Para calcular la efectividad de las vacunas primero hay que tener en cuenta la tasa de vacunación en Israel (un 80% de vacunados entre la población mayor de 12 años). Si calculamos la efectividad de la vacuna teniendo en cuenta este dato, obtenemos una efectividad del 67,5%.
¿Qué ocurre si dividimos por subgrupos de edad? Como sabemos desde el inicio de la pandemia, la probabilidad de enfermar por coronavirus de forma grave aumenta de forma drástica con la edad, por lo que esta es una variable de confusión. Es decir, que un enfermo de COVID-19 ingrese en un hospital no depende solo de que esté vacunado, sino que depende también de otros factores, como su edad.
De nuevo, igual que en el caso de los refrescos, además de esta variable de confusión había un subgrupo que desequilibraba la balanza: el de las personas mayores de 50 años vacunadas. De los 301 ingresados, 290 eran personas mayores de 50 años.
“Está descompensado porque la mayoría de gente que va a acabar en el hospital son mayores (otra cosa es que vayan menos que antes) pero es justo el grupo donde hay más gente vacunada”, explica a Maldita.es sobre este caso Javier Álvarez Liébana.
Por eso, si analizamos la efectividad de la vacuna en cada subgrupo de edad, vemos que es de un 91,8% entre los menores de 50 años y un 85,2% entre los mayores de 50 años.
*Hemos actualizado este artículo el 29 de septiembre de 2021 para añadir el ejemplo de los fallecidos en accidentes de tráfico.
**Hemos actualizado este artículo el 30 de septiembre de 2021 para citar adecuadamente a Influciencia.